defmain():parser=FlexibleArgumentParser(description="xFuser Arguments")args=xFuserArgs.add_cli_args(parser).parse_args()# Add Command Line Interface (CLI) argumentsengine_args=xFuserArgs.from_cli_args(args)# Extract CLI args and pass them to xFuserArgs Constructorengine_config,input_config=engine_args.create_config()# Init _WORLD. engine_config: model, run_time & parallel infos, input_config: input shape, prompt & sampler infoslocal_rank=get_world_group().local_rank
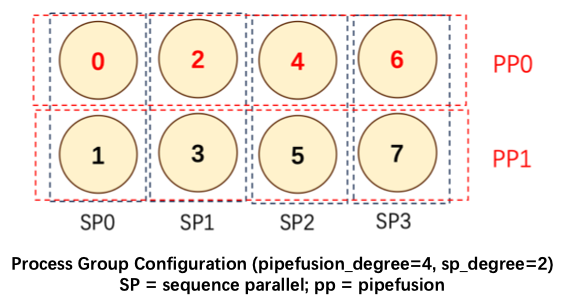
关于可以支持的并行策略如下,包括 Data Parallel, Sequence Parallel, Pipefusion Parallel & Tensor Parallel.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Parallel Processing Options:
--use_cfg_parallel Use split batch in classifier_free_guidance. cfg_degree will be 2ifset --data_parallel_degree DATA_PARALLEL_DEGREE
Data parallel degree.
--ulysses_degree ULYSSES_DEGREE
Ulysses sequence parallel degree. Used in attention layer.
--ring_degree RING_DEGREE
Ring sequence parallel degree. Used in attention layer.
--pipefusion_parallel_degree PIPEFUSION_PARALLEL_DEGREE
Pipefusion parallel degree. Indicates the number of pipeline stages.
--num_pipeline_patch NUM_PIPELINE_PATCH
Number of patches the feature map should be segmented in pipefusion parallel.
--attn_layer_num_for_pp [ATTN_LAYER_NUM_FOR_PP ...] List representing the number of layers per stage of the pipeline in pipefusion parallel
--tensor_parallel_degree TENSOR_PARALLEL_DEGREE
Tensor parallel degree.
--split_scheme SPLIT_SCHEME
Split scheme for tensor parallel.
pipe=xFuserPixArtAlphaPipeline.from_pretrained(# First construct a PixArtAlphaPipeline, then pass it and engine_config to xFuserPipelineBaseWrapperpretrained_model_name_or_path=engine_config.model_config.model,engine_config=engine_config,torch_dtype=torch.float16,).to(f"cuda:{local_rank}")pipe.prepare_run(input_config)
defgenerate_masked_orthogonal_rank_groups(world_size:int,parallel_size:List[int],mask:List[bool])->List[List[int]]:defprefix_product(a:List[int],init=1)->List[int]:# Exclusiver=[init]forvina:init=init*vr.append(init)returnrdefinner_product(a:List[int],b:List[int])->int:returnsum([x*yforx,yinzip(a,b)])defdecompose(index,shape,stride=None):# index: 第几个并行组 # shape: 并行组大小的 list"""
This function solve the math problem below:
There is an equation: index = sum(idx[i] * stride[i])
And given the value of index, stride.
Return the idx.
This function will used to get the pp/dp/pp_rank from group_index and rank_in_group.
"""ifstrideisNone:stride=prefix_product(shape)idx=[(index//d)%sfors,dinzip(shape,stride)]# 计算在每个并行维度上的索引# stride is a prefix_product result. And the value of stride[-1]# is not used.assert(sum([x*yforx,yinzip(idx,stride[:-1])])==index),"idx {} with shape {} mismatch the return idx {}".format(index,shape,idx)returnidxmasked_shape=[sfors,minzip(parallel_size,mask)ifm]# 需要采取并行的维度unmasked_shape=[sfors,minzip(parallel_size,mask)ifnotm]# 不需要的global_stride=prefix_product(parallel_size)# exclusive 前缀积 表示大的并行维度包括几个设备masked_stride=[dford,minzip(global_stride,mask)ifm]unmasked_stride=[dford,minzip(global_stride,mask)ifnotm]group_size=prefix_product(masked_shape)[-1]# 最大的一个并行维度包括几个设备num_of_group=world_size//group_size# 分成几个大组ranks=[]forgroup_indexinrange(num_of_group):# 遍历每个设备组# get indices from unmaksed for group_index.decomposed_group_idx=decompose(group_index,unmasked_shape)# 得到在不需要采取并行的维度上的索引rank=[]forrank_in_groupinrange(group_size):# 遍历该组中的每个设备 local rank# get indices from masked for rank_in_group.decomposed_rank_idx=decompose(rank_in_group,masked_shape)# 得到最大并行组的每个设备在采取并行的维度上的索引rank.append(//相加得到全局rankinner_product(decomposed_rank_idx,masked_stride)+inner_product(decomposed_group_idx,unmasked_stride))ranks.append(rank)returnranks
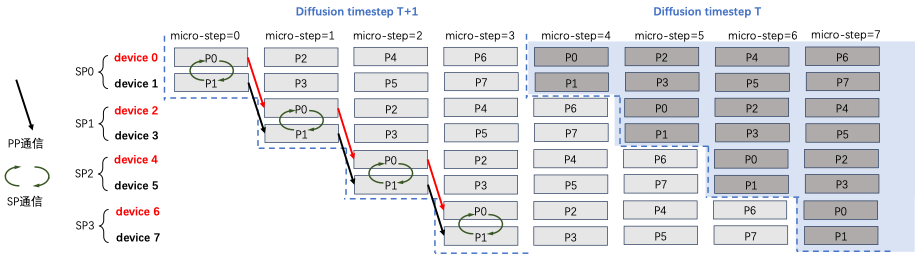
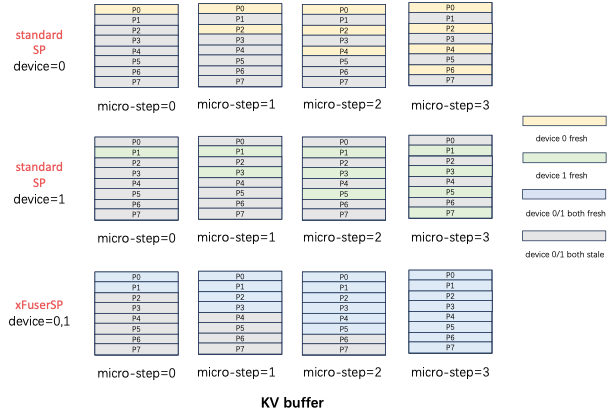
iflen(timesteps)==0:returnlatentsnum_pipeline_patch=get_runtime_state().num_pipeline_patchnum_pipeline_warmup_steps=get_runtime_state().runtime_config.warmup_stepspatch_latents=self._init_async_pipeline(num_timesteps=len(timesteps),latents=latents,num_pipeline_warmup_steps=num_pipeline_warmup_steps,)last_patch_latents=(# 每个 pipeline group 最后的设备接收所有的 patch[Nonefor_inrange(num_pipeline_patch)]if(is_pipeline_last_stage())elseNone)def_init_async_pipeline(self,num_timesteps:int,latents:torch.Tensor,num_pipeline_warmup_steps:int,):get_runtime_state().set_patched_mode(patch_mode=True)ifis_pipeline_first_stage():# get latents computed in warmup stage# ignore latents after the last timesteplatents=(get_pp_group().pipeline_recv()ifnum_pipeline_warmup_steps>0elselatents)patch_latents=list(latents.split(get_runtime_state().pp_patches_height,dim=2))elifis_pipeline_last_stage():patch_latents=list(latents.split(get_runtime_state().pp_patches_height,dim=2))else:patch_latents=[Nonefor_inrange(get_runtime_state().num_pipeline_patch)]recv_timesteps=(num_timesteps-1ifis_pipeline_first_stage()elsenum_timesteps)# construct receive tasks for each patchfor_inrange(recv_timesteps):forpatch_idxinrange(get_runtime_state().num_pipeline_patch):get_pp_group().add_pipeline_recv_task(patch_idx)returnpatch_latents
first_async_recv=Truefori,tinenumerate(timesteps):forpatch_idxinrange(num_pipeline_patch):ifis_pipeline_last_stage():last_patch_latents[patch_idx]=patch_latents[patch_idx]ifis_pipeline_first_stage()andi==0:passelse:iffirst_async_recv:get_pp_group().recv_next()first_async_recv=Falsepatch_latents[patch_idx]=get_pp_group().get_pipeline_recv_data(idx=patch_idx)patch_latents[patch_idx]=self._backbone_forward(latents=patch_latents[patch_idx],prompt_embeds=prompt_embeds,prompt_attention_mask=prompt_attention_mask,added_cond_kwargs=added_cond_kwargs,t=t,guidance_scale=guidance_scale,)ifis_pipeline_last_stage():patch_latents[patch_idx]=self._scheduler_step(patch_latents[patch_idx],# pred noiselast_patch_latents[patch_idx],# last timestep noiset,extra_step_kwargs,)ifi!=len(timesteps)-1:get_pp_group().pipeline_isend(patch_latents[patch_idx],segment_idx=patch_idx)else:get_pp_group().pipeline_isend(patch_latents[patch_idx],segment_idx=patch_idx)ifis_pipeline_first_stage()andi==0:passelse:ifi==len(timesteps)-1andpatch_idx==num_pipeline_patch-1:passelse:get_pp_group().recv_next()get_runtime_state().next_patch()# switch to next: (self.pipeline_patch_idx + 1) % self.num_pipeline_patchifi==len(timesteps)-1or((i+num_pipeline_warmup_steps+1)>num_warmup_stepsand(i+num_pipeline_warmup_steps+1)%self.scheduler.order==0):progress_bar.update()assertcallbackisNone,"callback not supported in async ""pipeline"if(callbackisnotNoneandi+num_pipeline_warmup_steps%callback_steps==0):step_idx=(i+num_pipeline_warmup_steps)//getattr(self.scheduler,"order",1)callback(step_idx,t,patch_latents[patch_idx])
classPatchConv2d(nn.Conv2d):def__init__(self,in_channels:int,out_channels:int,kernel_size:_size_2_t,stride:_size_2_t=1,padding:Union[str,_size_2_t]=0,dilation:_size_2_t=1,groups:int=1,bias:bool=True,padding_mode:str='zeros',# TODO: refine this typedevice=None,dtype=None,block_size:Union[int,Tuple[int,int]]=0)->None:ifisinstance(dilation,int):assertdilation==1,"dilation is not supported in PatchConv2d"else:foriindilation:asserti==1,"dilation is not supported in PatchConv2d"self.block_size=block_sizesuper().__init__(in_channels,out_channels,kernel_size,stride,padding,dilation,groups,bias,padding_mode,device,dtype)
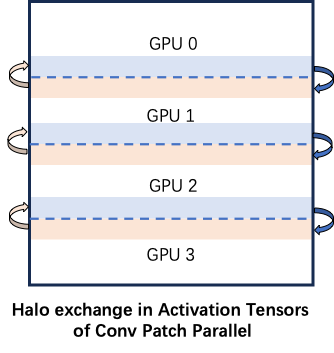
to_next=Noneto_prev=Nonetop_halo_recv=Nonebottom_halo_recv=Noneifnext_top_halo_width>0:bottom_halo_send=input[:,:,-next_top_halo_width:,:].contiguous()to_next=dist.isend(bottom_halo_send,rank+1)ifhalo_width[0]>0:# not rank 0top_halo_recv=torch.empty([bs,channels,halo_width[0],w],dtype=input.dtype,device=f"cuda:{rank}")dist.recv(top_halo_recv,rank-1)ifprev_bottom_halo_width>0:# not rank N-1top_halo_send=input[:,:,:prev_bottom_halo_width,:].contiguous()to_prev=dist.isend(top_halo_send,rank-1)ifhalo_width[1]>0:bottom_halo_recv=torch.empty([bs,channels,halo_width[1],w],dtype=input.dtype,device=f"cuda:{rank}")dist.recv(bottom_halo_recv,rank+1)
拼接 halo 区域
1
2
3
4
5
6
7
ifhalo_width[0]<0:# Remove redundancy at the top of the inputinput=input[:,:,-halo_width[0]:,:]iftop_halo_recvisnotNone:# concat the halo region to the input tensor input=torch.cat([top_halo_recv,input],dim=-2)ifbottom_halo_recvisnotNone:input=torch.cat([input,bottom_halo_recv],dim=-2)
padding=self._adjust_padding_for_patch(self._reversed_padding_repeated_twice,rank=rank,world_size=world_size)ifself.block_size==0or(h<=self.block_sizeandw<=self.block_size):ifself.padding_mode!='zeros':conv_res=F.conv2d(F.pad(input,padding,mode=self.padding_mode),weight,bias,self.stride,_pair(0),self.dilation,self.groups)else:conv_res=F.conv2d(input,weight,bias,self.stride,self.padding,self.dilation,self.groups)returnconv_reselse:ifself.padding_mode!="zeros":input=F.pad(input,padding,mode=self.padding_mode)elifself.padding!=0:input=F.pad(input,padding,mode="constant")_,_,h,w=input.shapenum_chunks_in_h=(h+self.block_size-1)//self.block_size# h 维度的 block 数量num_chunks_in_w=(w+self.block_size-1)//self.block_size# w ...unit_chunk_size_h=h//num_chunks_in_hunit_chunk_size_w=w//num_chunks_in_woutputs=[]foridx_hinrange(num_chunks_in_h):inner_output=[]foridx_winrange(num_chunks_in_w):start_w=idx_w*unit_chunk_size_wstart_h=idx_h*unit_chunk_size_hend_w=(idx_w+1)*unit_chunk_size_wend_h=(idx_h+1)*unit_chunk_size_h# 计算每个块的开始和结束索引,调整块的边界# ...# 对当前块执行卷积操作inner_output.append(F.conv2d(input[:,:,start_h:end_h,start_w:end_w],weight,bias,self.stride,0,self.dilation,self.groups,))outputs.append(torch.cat(inner_output,dim=-1))returntorch.cat(outputs,dim=-2)