GPU Architecture
典型的 GPU 包含一系列流多处理器 (Stream Multi-processor, SM),每个多处理器都有许多内核 (core). GPU 具有高度并行性,可以同时执行多项任务。
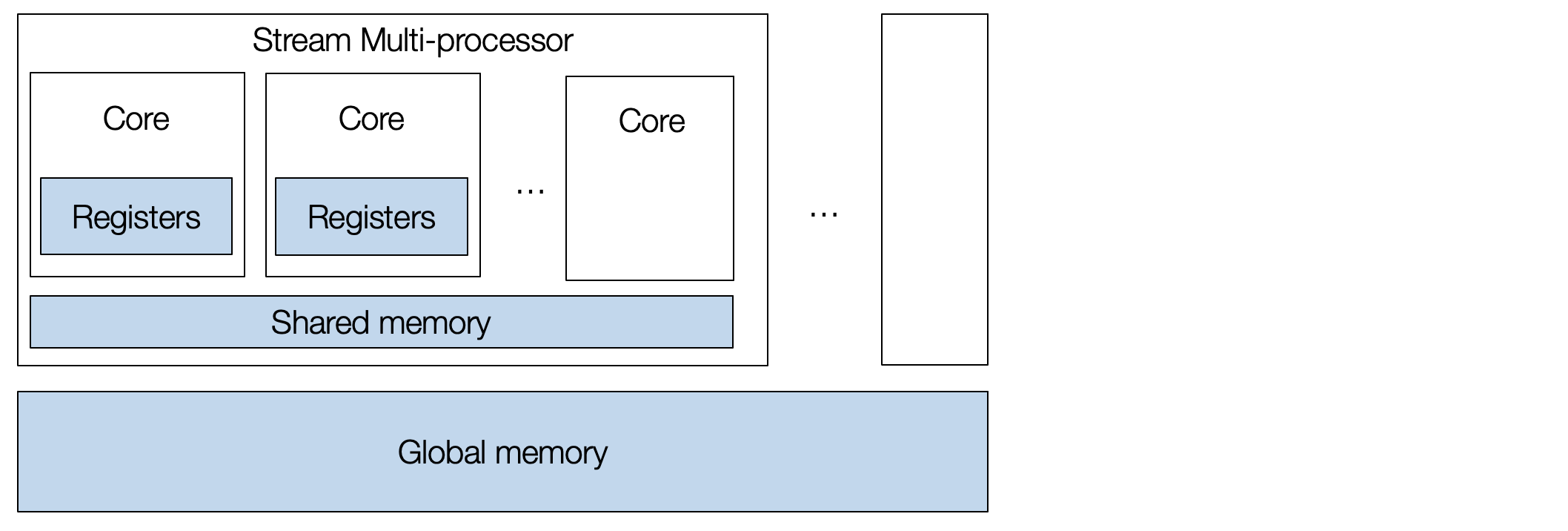
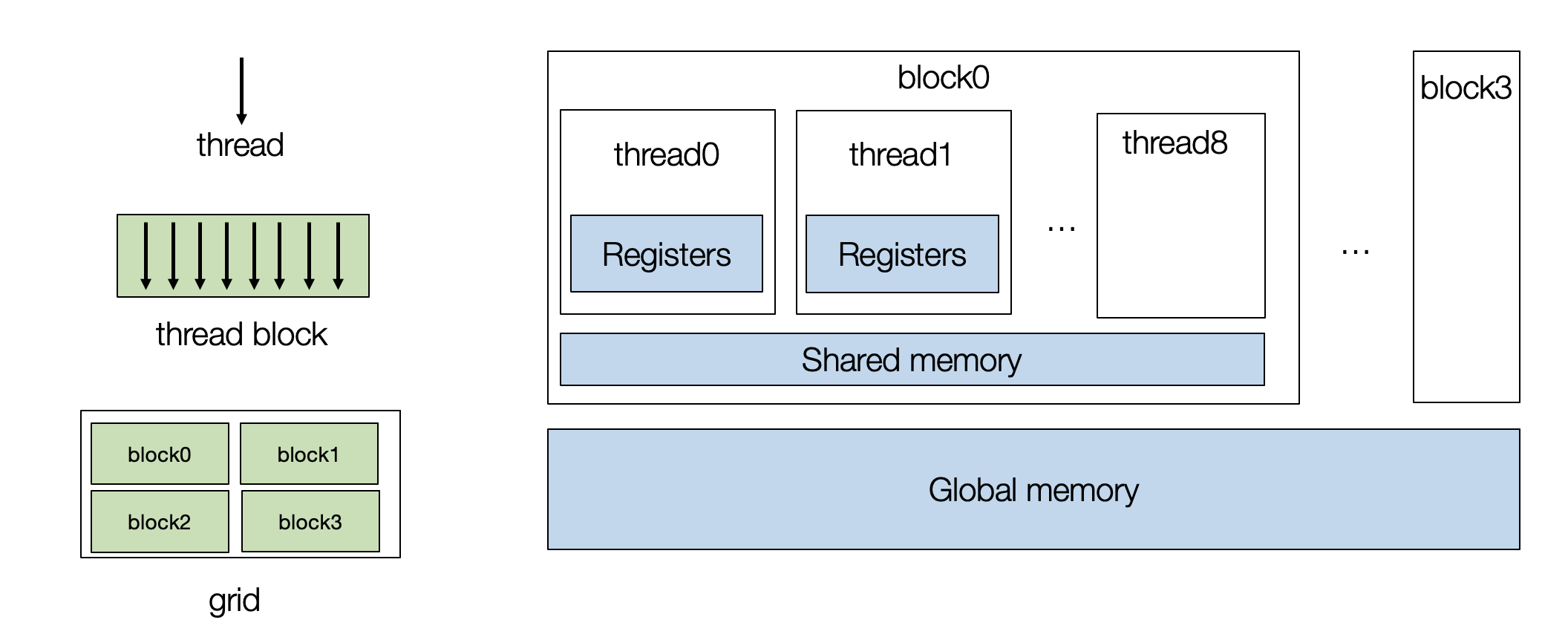
要对 GPU 进行编程,我们需要创建一组线程块 (thread blocks),每个 thread 映射到单个核心,而 block 映射到流式多处理器 (SM)。
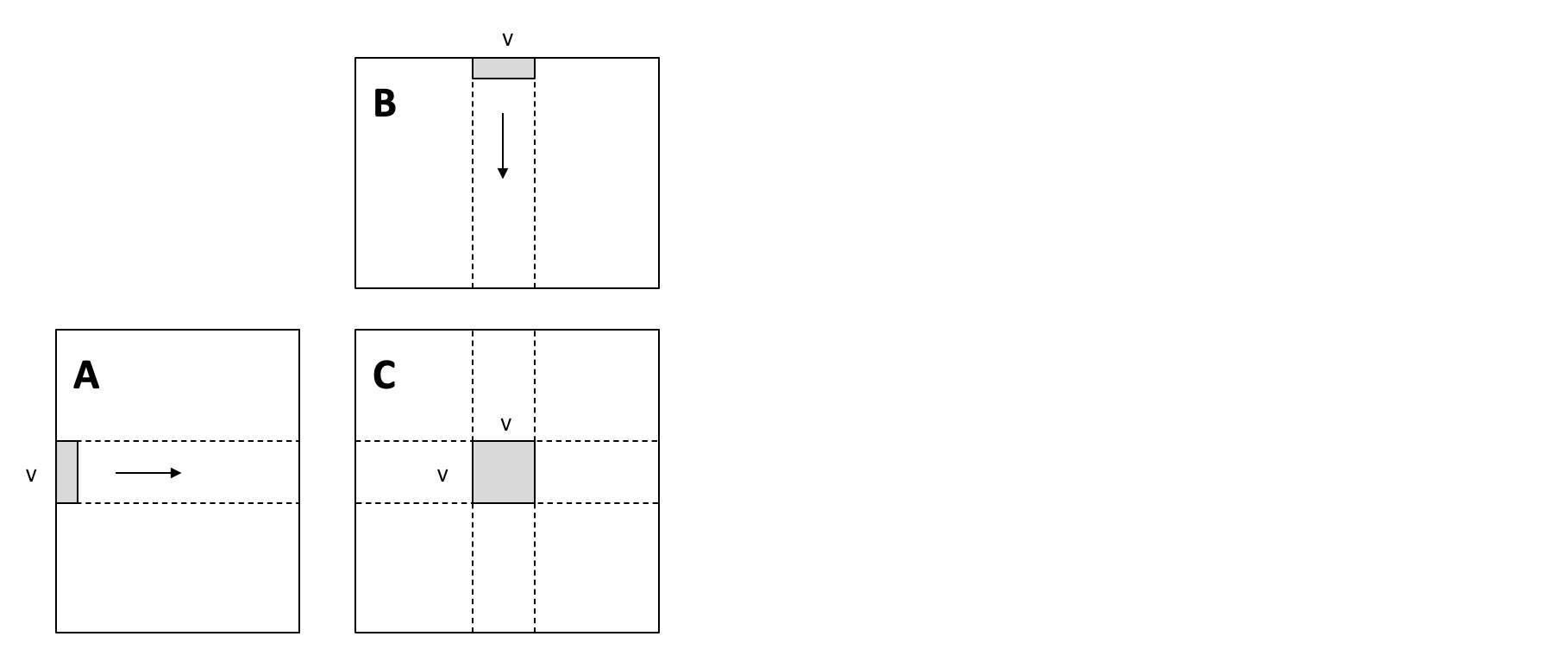
我们以两个长度为1024的向量加法 C=A+B为例,我们先把外循环 split 成两部分
| |
得到的 TensorIR 如下
| |
Build and Run the TensorIR Function on GPU
一个CUDA程序的计算被组织成三层次:网格(Grid)、线程块(Block)和线程(Thread)。网格是一个二维的数组,包含多个线程块。每个线程块也是一个二维的数组,包含多个线程。每个线程执行相同的代码,但是在执行时可以使用不同的数据。每个线程由两个索引进行表示 threadIdx.x和 blockIdx.x. 在实际应用中,有多维线程索引,但这里我们为了简化问题,将它们固定为一维表示。

sch.bind(i0, "blockIdx.x")将i0循环绑定到 GPU 的 block 索引,以便将计算分发到不同的 GPU block 上。sch.bind(i1, "threadIdx.x")将i1循环绑定到 GPU 的 thread 索引,以便将计算分发到每个 block 内的不同的 GPU thread 上。
可以看到循环变量变成了 T.thead_binding
| |
然后我们可以在GPU上构建并测试程序的正确性
| |
Window Sum Example
滑动窗口求和可以被视为权重为 [1,1,1]的卷积,对输入进行滑动并将三个相邻值相加。

跟上一节一样我们将循环split后把外循环和内循环分别bind到block和thread上
| |
对应的TensorIR如下
| |
Cache in Shared Memory
我们可以看到在窗口滑动的过程中有一部分数据是重复的。每个 block 包含所有线程都可以在块内访问的共享内存 (shared memory),为了避免重复从 global memory 加载,我们可以把部分数据缓存到共享内存上
B[vi] = A[vi] + A[vi + 1] + A[vi + 2]这一行代码会重复读取A缓冲区中的数据。sch.cache_read(block_C, read_buffer_index=0, storage_scope="shared")创建了一个名为A_shared的共享内存缓存,用于存储A缓冲区中的一部分数据。
block_C指示缓存与Cblock 相关联。read_buffer_index=0指示缓存A缓冲区,因为A是Cblock 中的第一个读取缓冲区。storage_scope="shared"指示缓存使用共享内存。
sch.compute_at(A_shared, i1)将A_shared的计算位置设置为i1循环,这意味着A_shared将在每个 thread 中被计算。
| |
变换后的TensorIR如下,主要进行了
共享内存分配: 在每个 GPU block 的共享内存中分配了一个大小为
(1027,)的缓冲区A_shared。A_shared = T.alloc_buffer((1027,), scope="shared")添加了一个新的 block
A_shared,循环遍历每个 thread并将A缓冲区中的数据缓存到A_shared中:for i_0 in T.thread_binding(8, thread="blockIdx.x"): for i_1 in T.thread_binding(128, thread="threadIdx.x"): for ax0 in range(130): with T.block("A_shared"): v0 = T.axis.spatial(1027, i_0 * 128 + ax0) T.reads(A[v0]) T.writes(A_shared[v0]) A_shared[v0] = A[v0]码更新了
Cblock 中的计算,使其从A_shared中读取数据:with T.block("C"): vi = T.axis.spatial(1024, i_0 * 128 + i_1) T.reads(A_shared[vi:vi + 3]) T.writes(B[vi]) B[vi] = A_shared[vi] + A_shared[vi + 1] + A_shared[vi + 2]
rane(130) 的出现是因为需要将 A 缓冲区中的数据缓存到共享内存 A_shared 中。每个 GPU block 处理的数据范围是 128 个元素,对应于 i1 循环的范围。由于窗口求和操作需要访问 A 缓冲区中当前元素的三个相邻元素,因此每个 thread 需要访问 128 + 2 = 130 个元素。为了确保每个 thread 都能访问到所需的数据,需要将 A 缓冲区中 130 个元素缓存到 A_shared 中。
| |
Get CUDA Source
我们可以检查相应的底层代码(CUDA )
| |
生成的代码包含两部分:
- 在主机 (CPU) 上的调用 GPU 程序的部分;
- 相应计算的 CUDA 内核。
| |
Matrix Multiplication
下面我们对原始的 1024*1024的矩阵乘法进行优化
| |
Local Blocking
下面的blocking 函数使用了一种称为 局部阻塞 的优化策略,将矩阵乘法的计算分解成更小的块,并使用共享内存缓存来提高性能。
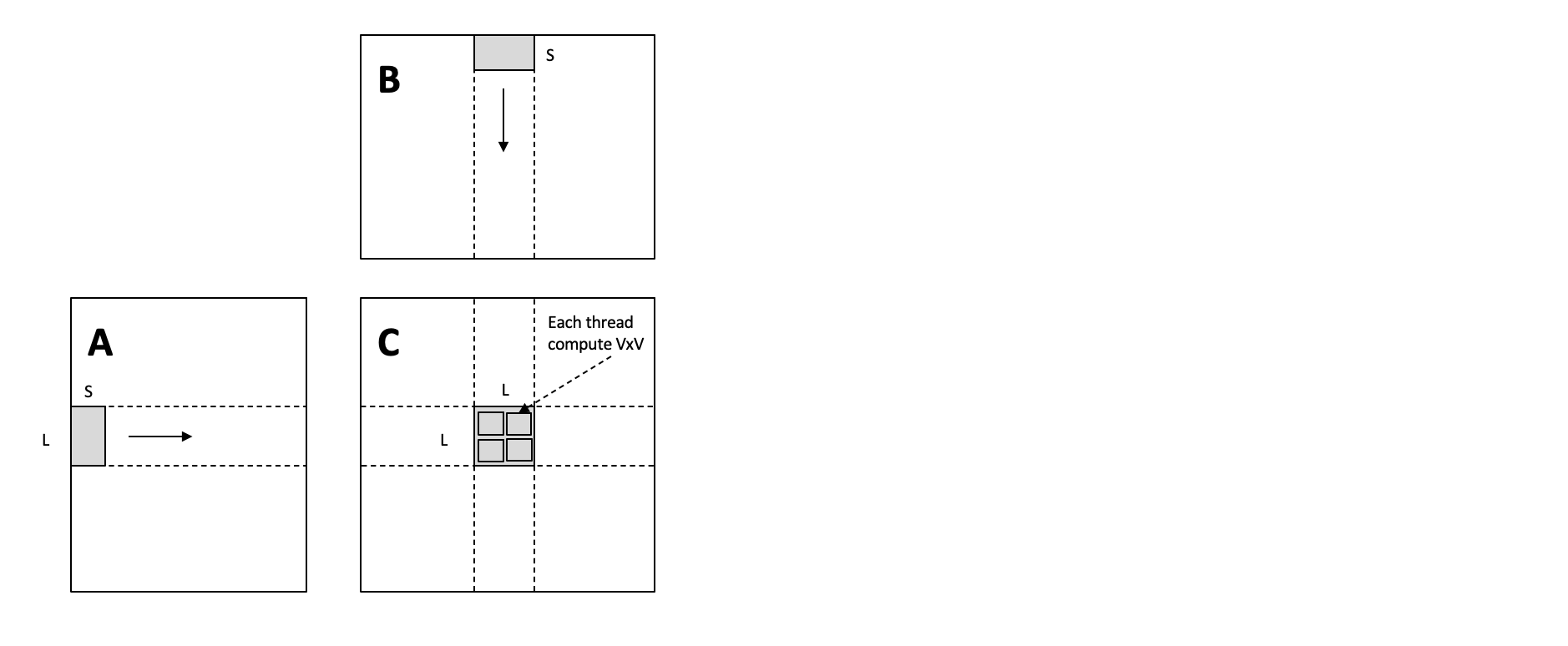
- 将三个循环
i、j和k分别拆分成多个循环,例如将i拆分成i0、i1和i2,分别对应于 block 索引、thread 索引和局部循环索引。 k1表示矩阵计算被拆分成多少个小块,k0决定了每个线程需要进行多少次累加操作。调整循环的顺序,以便在每个 thread 中计算k0循环的所有迭代,从而利用共享内存缓存。- 使用
cache_write函数创建一个名为C_local的共享内存缓存,用于存储C矩阵的中间结果。 - 使用
reverse_compute_at函数将C_local的计算位置设置为j1循环,以便在每个 thread 中计算C_local的所有迭代,从而利用共享内存缓存。 - 将
i0和j0绑定到 GPU 的blockIdx.y和blockIdx.x线程索引,将i1和j1绑定到 GPU 的threadIdx.y和threadIdx.x线程索引。 - 使用
unroll函数展开k1循环,以便在每个 thread 中展开计算,从而提高性能。 - 使用
decompose_reduction函数分解k0循环,以便在每个 thread 中计算k0循环的所有迭代,从而利用共享内存缓存。
| |
进行 Local Blocking 后的TensorIR如下
| |
Shared Memory Blocking
上面的方法没有考虑相邻 thread 位于同一个 block 中,我们可以将它们需要的数据加载到 shared memory 中。
cache_read_and_coop_fetch 函数负责将 A 和 B 矩阵中的数据加载到共享内存中。首先使用 cache_read 创建一个共享内存缓存,用于存储 A 或 B 矩阵的数据。然后使用 compute_at 将缓存的计算位置设置为 k0 循环,在每个线程中计算缓存的所有迭代。最后使用 split 和 vectorize 函数对 k0 循环进行向量化,提高加载数据的效率。
| |
其余的操作和 Local Blocking 一致
| |