E2E Model Integration
我们以下图中的 MLP 网络为例,这是一个两层全连接网络,并且省略了最后的 Softmax 层。
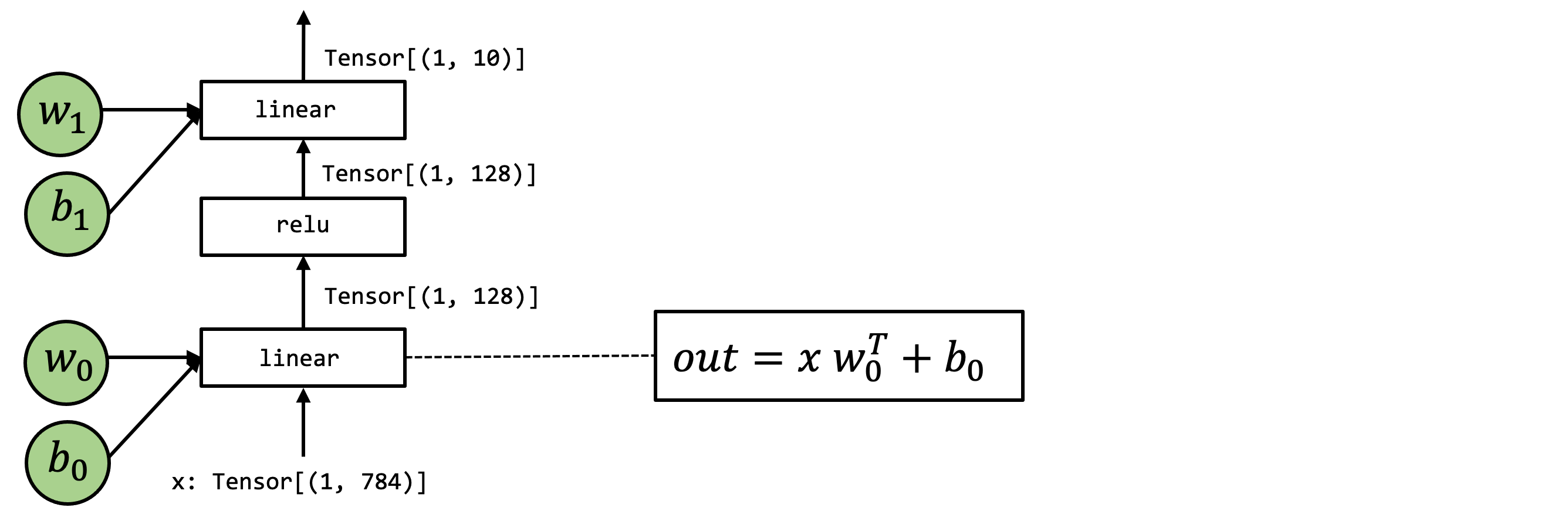
利用高级Numpy的实现如下
| |
为了方便说明底层计算过程,用 Low-level Numpy 进行重写后如下
| |
Constructing an E2E IRModule in TVMScript
同样可以用 TVMScript 构建这个网络的 IRModule,只不过这次除了要用 Primitive Tensor Function (@T.prim_function) 还要用 Relax Function (@R.function) 来抽象神经网络的计算过程。
| |
Computational Graph View
该网络的计算图如下,计算图通常具有以下性质:
- 框的每个输入边对应于操作的输入;
- 每个出边对应于操作的输出;
- 可以任意调整操作的顺序,只要保证边的拓扑排序(Topological Order)没有改变。
Topological Order
拓扑排序是针对有向无环图 (DAG) 的一种排序算法,它将图中的节点排成一个线性序列,满足以下条件:
- 对于图中的任意一条边 (u, v),节点 u 在排序中都出现在节点 v 之前。
进行拓扑排序较常用的方法:
- 从 DAG 图中选择一个 没有前驱(即入度为0)的顶点并输出。
- 从图中删除该顶点和所有以它为起点的有向边。
- 重复 1 和 2 直到当前的 DAG 图为空或 当前图中不存在无前驱的顶点为止 。后一种情况说明有向图中必然存在环。

R.call_tir
R.call_tir 正如名字一样调用一个 T.prim_func 并返回计算结果。它的行为用Numpy表示如下,先根据 shape和 dtype开辟输出数据的内存空间,然后调用函数,最后返回输出结果。R.call_tir函数的输入是这种形式的原因是 T.prim_func函数的输入需要我们先为输出结果开辟内存,称为 目标传递 (destination passing) 。
| |
为了让程序执行具有计算图的性质,我们采用这种方式进行调用
| |
Dataflow Block
理想情况下,计算图中的操作应为 side-effect free,即一个函数只从其输入中读取并通过其输出返回结果,不会改变程序的其他部分(例如递增全局计数器)。如果要引入包含 side-effect 的操作,就需要定义多个dataflow block,在他们之外或者之间进行操作。
| |
Build and Run the Model
该网络对应的TensorIR如下
| |
我们可以通过下面方式来构造 virtual machine. relax.build返回一个 tvm.relax.Executable对象,然后就可以在指定的硬件上创建virtual machine 来执行计算图。
| |
Integrate Existing Libraries in the Environment
除了用 T.prim_func构造RelaxIR,我们也可以从现有的深度学习库的函数来构造。
这是通过 R.call_dps_packed来完成的,它用于调用一个目标传递风格 (Destination-Passing Style) 的打包函数 (Packed Function),并返回输出结果。
目标传递风格 (Destination-Passing Style): 目标传递风格是一种函数调用方式,其中函数的输出参数作为函数参数传递给函数。 打包函数 (Packed Function): 打包函数是一种函数,其输入参数和输出参数都被打包成一个结构体。 纯函数 (Pure Function): 纯函数是指不产生副作用的函数,即函数的执行结果只依赖于输入参数,并且不会修改任何全局状态。
示例:
| |
函数参数:
func: 可以是字符串或表达式,表示目标传递风格的函数。如果func是字符串,它将被转换为ExternFunc对象。args: 表达式,表示输入参数。如果args是单个表达式,它将被包装成一个RxTuple对象。out_sinfo: 可以是TensorStructInfo对象或TensorStructInfo对象列表,表示call_dps_packed函数输出的结构信息。每个TensorStructInfo对象表示一个返回的张量的结构信息。
函数返回值:
ret:Call对象,表示call_dps_packed操作符的调用节点。
Registering Runtime Function
为了能够执行调用外部函数的代码,我们需要注册相应的函数。下面这段代码注册了两个自定义函数,分别用于实现线性层和 ReLU 激活函数。
@tvm.register_func("env.linear", override=True):- 使用
@tvm.register_func装饰器将torch_linear函数注册为名为"env.linear"的 TVM 函数。 override=True表示如果已经存在同名函数,则覆盖它。
- 使用
torch_linear(x: tvm.nd.NDArray, w: tvm.nd.NDArray, b: tvm.nd.NDArray, out: tvm.nd.NDArray):- 该函数接受四个参数:
x: 输入张量。w: 权重张量。b: 偏置张量。out: 输出张量。
- 函数内部:
- 使用
torch.from_dlpack将 TVM 的NDArray对象转换为 PyTorch 的Tensor对象。 - 使用 PyTorch 的
torch.mm函数进行矩阵乘法,将x和w的转置相乘,并将结果写入out。 - 使用 PyTorch 的
torch.add函数将b加到out上。
- 使用
- 该函数接受四个参数:
@tvm.register_func("env.relu", override=True):- 使用
@tvm.register_func装饰器将lnumpy_relu函数注册为名为"env.relu"的 TVM 函数。 override=True表示如果已经存在同名函数,则覆盖它。
- 使用
lnumpy_relu(x: tvm.nd.NDArray, out: tvm.nd.NDArray):- 该函数接受两个参数:
x: 输入张量。out: 输出张量。
- 函数内部:
- 使用
torch.from_dlpack将 TVM 的NDArray对象转换为 PyTorch 的Tensor对象。 - 使用 PyTorch 的
torch.maximum函数计算x和 0 之间的最大值,并将结果写入out。
- 使用
- 该函数接受两个参数:
| |
然后我们就可以创建IRModule并通过上一节所说方法去 build and run.
| |
Mixing TensorIR Code and Libraries
我们可以混合使用T.prim_func和 注册的 runtime 函数来创建 RelaxIR. 以下代码展示了一个例子,其中 linear0 仍在 TensorIR 中实现,而其他函数则被重定向到库函数中。
| |
Bind Parameters to IRModule
之前都是通过显示传递参数给 vm["main"]函数来调用,我们也可以将参数当作常熟与IRModule进行绑定。
metadata["relax.expr.Constant"]对应的是存储常量的隐式字典(虽然没有显示在脚本中,但仍是 IRModule 的一部分)。构建了转换后的 IRModule,现在只需输入数据就可以调用函数。
| |